:format(webp))
The Hopper and Blackwell GPU architectures represent successive generations of NVIDIA’s datacenter accelerators. Hopper powers the H100 and H200 GPUs and introduced fourth-generation Tensor Cores with an FP8 Transformer Engine, enabling up to 9× faster training and 30× faster inference compared with the A100 [Nvidia Developer Blog]. Blackwell, announced in March 2024 but only shipping in late 2024/early 2025, combines two dies via a 10 TB/s NV-HBI interface, adds FP4 precision, and uses fifth-generation NVLink to deliver up to 30× cluster inference performance. [Nvidia Datasheet]
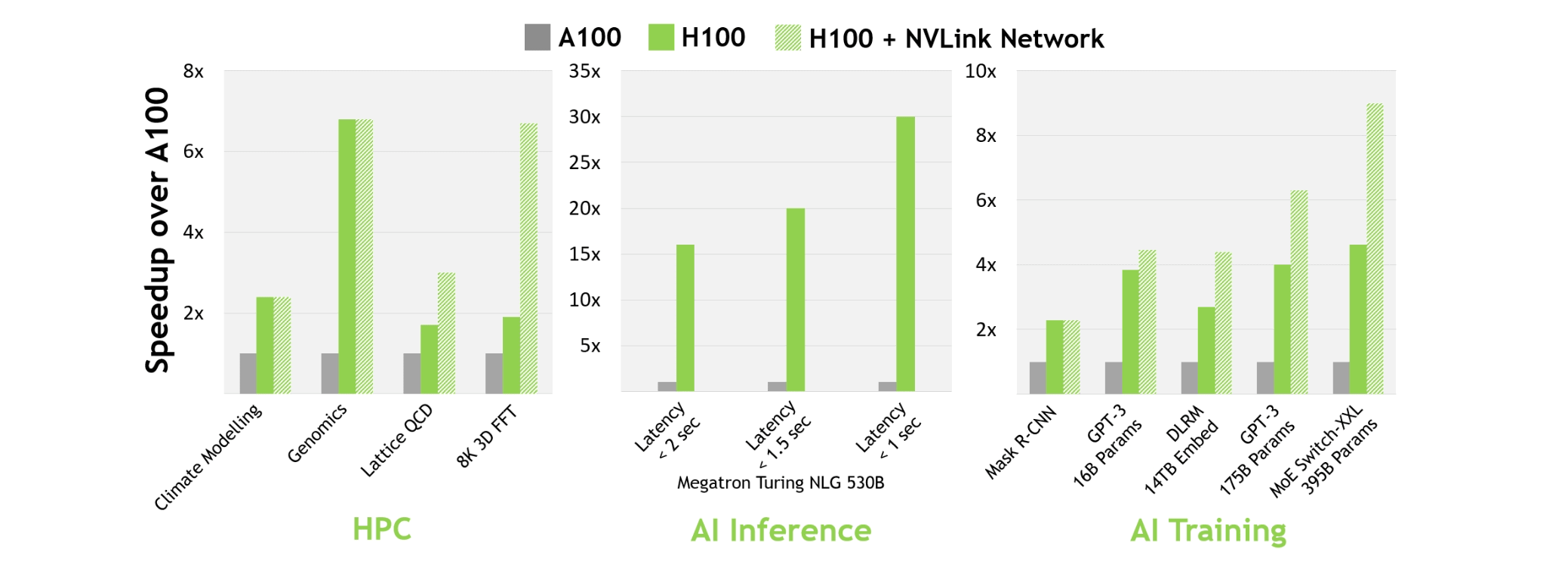
This article examines both architectures’ specs, practical performance, and availability, with a focus on AI/ML engineers and SMB use cases.
Hopper Architecture (H100 & H200)
Key Features
Tensor Cores & Transformer Engine: FP8/FP16/TF32 mixing for attention and matrix ops.
Memory: H100 uses 80 GB HBM3 at 3.35 TB/s; H200 uses 141 GB HBM3e at 4.8 TB/s.
Interconnect: Up to 900 GB/s NVLink per GPU for multi-node scaling.
Practical Implications
Independent tests show H200 can boost inference on large LLMs (e.g., Llama-2 70B) by ~45–100% over H100 . However, both GPUs faced supply shortages in 2023–2025 due to packaging constraints and hyperscaler pre-orders. Hyperbolic's On-demand Cloud provides H100 virtual machines and bare-metal multi-node clusters with Ethernet and InfiniBand starting at $1.49 per hour. H200s and B200s are available upon request with an instant quote via our Reserve Deals.
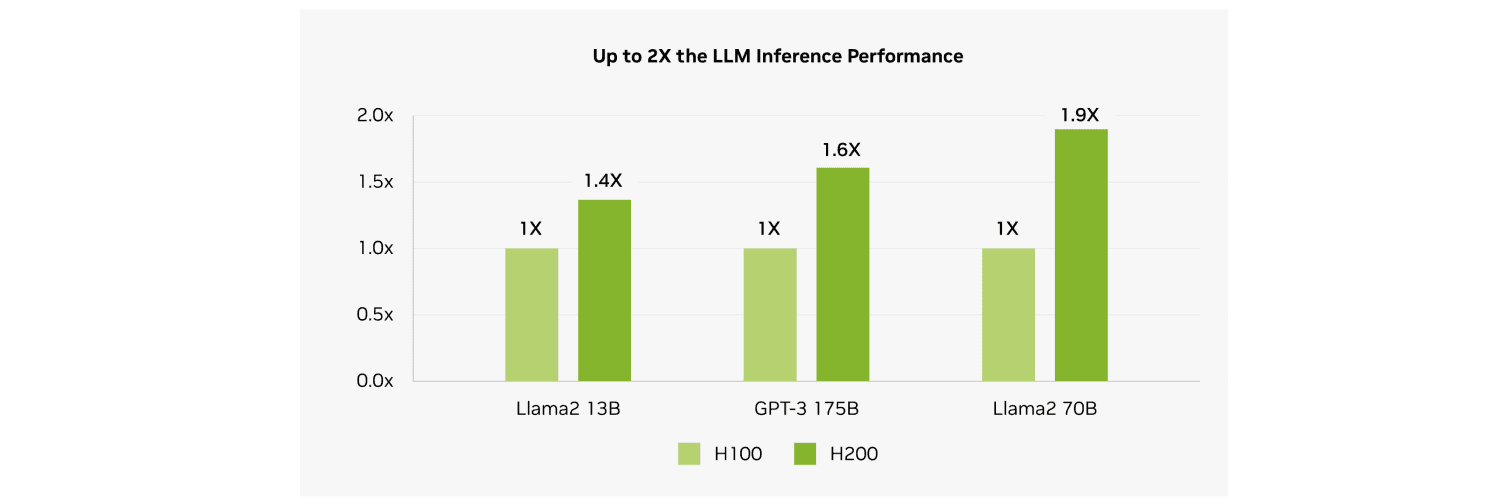
Image Source: [Nvidia H200 Tensor Core GPU]
Blackwell Architecture (B200)
Innovations
Chiplet Design: Two dies on TSMC 4NP, 208 billion transistors, 10 TB/s NV-HBI.
Transformer Engine: Adds FP4 precision and enhanced FP8:
NVLink-5: 18 links, 1.8 TB/s total per GPU.
Decompression Engine: 800 GB/s CPU↔GPU.
RAS & Confidential Compute: Memory error protection and encryption.
Performance Metrics
GPU | Memory | Bandwidth | FP8 | FP16/BF16 | FP32 | FP64 | NVLink | TDP |
|---|---|---|---|---|---|---|---|---|
H100 SXM | 80 GB HBM3 | 3.35 TB/s | 3.958 PFLOPS | 1.979 PFLOPS | 67 TFLOPS | 34 TFLOPS | 900 GB/s | 700 W |
H200 SXM | 141 GB HBM3e | 4.8 TB/s | 3.958 PFLOPS | 1.979 PFLOPS | 67 TFLOPS | 34 TFLOPS | 900 GB/s | 700 W |
HGX B200 | 180 GB HBM3e | 7.7 TB/s | 9 PFLOPS | 4.5 PFLOPS | 75 TFLOP | 37 TFLOPS | 1.8 TB/s | 1,000 W |
Metrics Sources: [Nvidia H100 Tensor Core GPU], [Nvidia H200 Tensor Core GPU], [Nvidia Blackwell Datasheet]
What is a FLOP?
A FLOP (floating-point operation) measures a single arithmetic calculation, like adding or multiplying two numbers. A TFLOP, or teraflop, means a trillion (10¹²) of those operations per second, and a PFLOP, or petaflop, means a thousand trillion (10¹⁵) operations per second. In other words, a PFLOP is one thousand times more powerful than a TFLOP, and these metrics help compare how quickly different processors or supercomputers can perform the massive number-crunching tasks that underpin AI training, scientific simulations, and high-performance computing.
Practical Performance
HGX B200: Up to 15× inference and 3× training vs. HGX H100, with 12× energy/cost reduction.
GB200 NVL72 Cluster: 4× faster training, 30× faster real-time inference vs. H100 clusters.
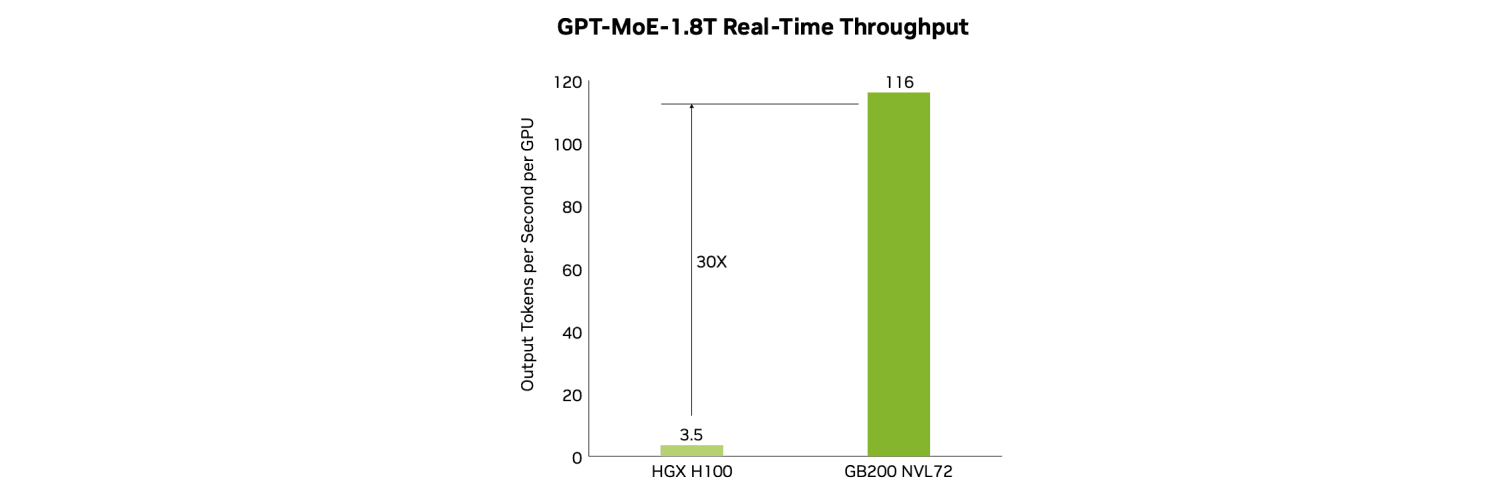
Image Source: [Nvidia Hopper Architecture In-Depth]
Conclusion
Hopper (H100/H200) introduced FP8 mixed precision and asynchronous pipelines, delivering a major uplift over A100. Blackwell (B200) adds FP4, more memory, and NVLink-5, promising up to 30× cluster inference gains. Hyperbolic's On-demand Cloud provides H100 virtual machines and bare-metal multi-node clusters with Ethernet and InfiniBand starting at $1.49 per hour. H200s and B200s are available upon request with an instant quote via our Reserve Deals. Until supply catches up, H100 remains the workhorse—especially when rented via Hyperbolic's On Demand—while H200 and Blackwell chart the path for next-generation AI infrastructure.
About Hyperbolic
Hyperbolic is the on-demand AI cloud made for developers. We provide fast, affordable access to compute, inference, and AI services. Over 195,000 developers use Hyperbolic to train, fine-tune, and deploy models at scale.
Our platform has quickly become a favorite among AI researchers, including those like Andrej Karpathy. We collaborate with teams at Hugging Face, Vercel, Quora, Chatbot Arena, LMSYS, OpenRouter, Black Forest Labs, Stanford, Berkeley, and beyond.
Founded by AI researchers from UC Berkeley and the University of Washington, Hyperbolic is built for the next wave of AI innovation—open, accessible, and developer-first.
Website | X | Discord | LinkedIn | YouTube | GitHub | Documentation
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))