:format(webp))
In a significant advancement for open-source AI, the Qwen team at Alibaba has unveiled Qwen-Image, a 20-billion-parameter Multimodal Diffusion Transformer (MMDiT) model designed for next-generation text-to-image generation. Announced today on X by the official Qwen account, this model stands out for its exceptional capabilities in creating stunning graphic posters with native, in-pixel text rendering, without relying on overlays. It's particularly strong in bilingual support for English and Chinese, handling diverse fonts and complex layouts, while also excelling in general image generation across styles like photorealistic, anime, impressionist, and minimalist.
This release builds on the Qwen series' foundation in multimodal AI, positioning Qwen-Image as a creative powerhouse that's now fully open-source, available on platforms like Hugging Face and GitHub. But what makes this model tick under the hood? Let's dive into its architecture, innovations, and practical implications. The citations in this article refer to the Official Qwen-Image Technical Report.
Model Architecture and How It Works
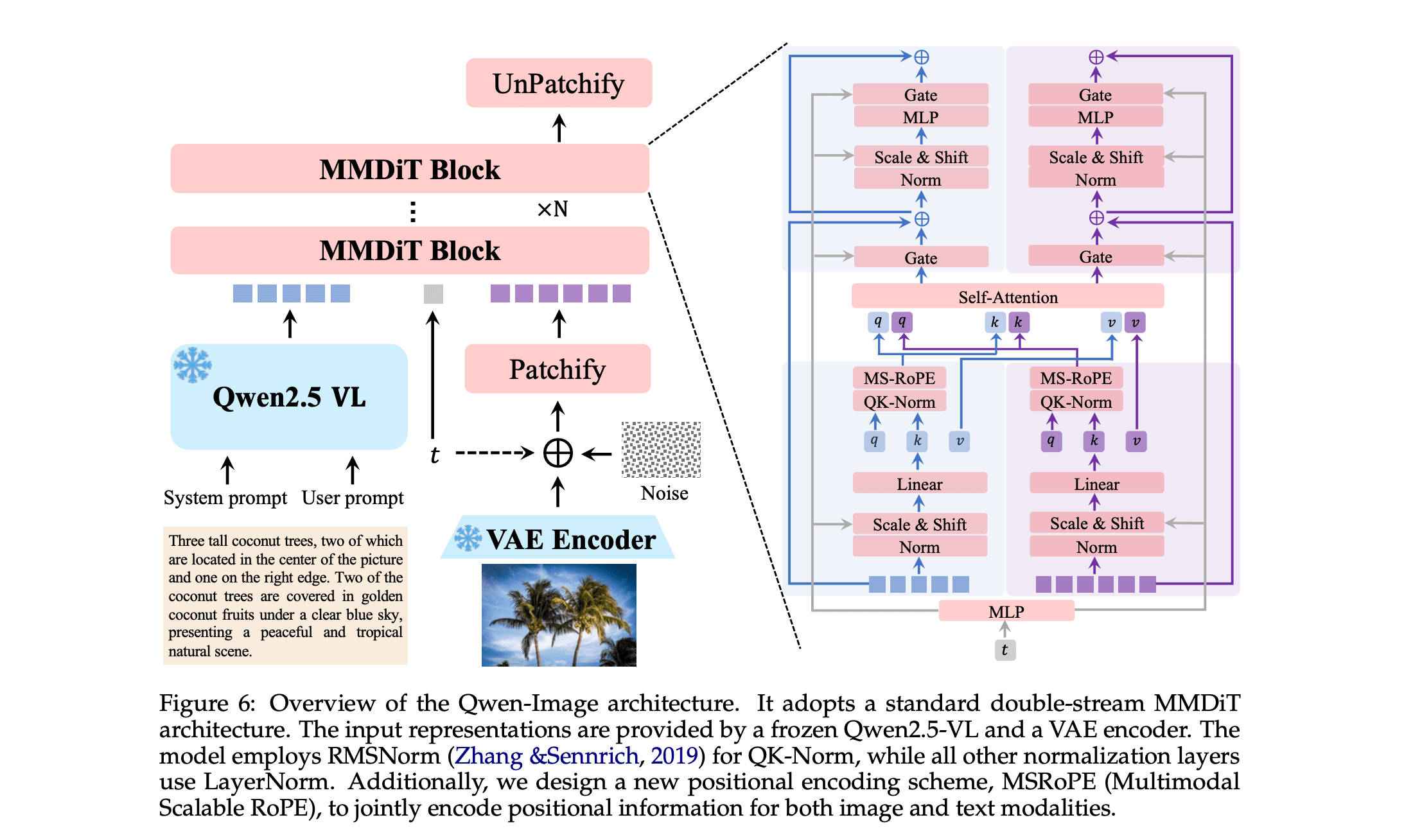
At its core, Qwen-Image integrates three key components: a Multimodal Large Language Model (MLLM), a Variational AutoEncoder (VAE), and the MMDiT itself, working in tandem to transform text prompts into high-fidelity images. [Official Qwen-Image Paper, Page 7-8]
Multimodal Large Language Model (MLLM): Qwen-Image leverages Qwen2.5-VL (a 7B-parameter model) for extracting rich semantic features from textual inputs. This MLLM processes prompts with tailored system instructions for tasks like text-to-image (T2I) or text-image-to-image (TI2I), using the last layer's hidden states as representations. This ensures deep language understanding, enabling the model to handle intricate descriptions. [Official Qwen-Image Paper, Page 7]
Variational AutoEncoder (VAE): A single-encoder, dual-decoder VAE is employed, with the encoder frozen from Wan-2.1-VAE and the image decoder fine-tuned on text-rich datasets (e.g., PDFs, posters, synthetic paragraphs). This setup minimizes artifacts like grid patterns and enhances reconstruction fidelity, especially for small texts. Losses are balanced between reconstruction and perceptual metrics for optimal quality. [Official Qwen-Image Paper, Page 8]
Multimodal Diffusion Transformer (MMDiT): The 20B-parameter heart of the system, MMDiT jointly models text and image latents using flow matching with ODEs (Ordinary Differential Equations, which are mathematical equations describing how a quantity changes continuously over time; in this context, they define a smooth "flow" from noise to generated data during training, enabling efficient sampling and generation). Text features are treated as 2D tensors and concatenated diagonally with image latents, allowing for scalable resolutions. [Official Qwen-Image Paper, Page 8]
The generation process begins with a text prompt fed into the MLLM for feature extraction. These features condition the MMDiT, which denoises a noisy latent representation step-by-step. The VAE then decodes this into the final image. For editing (TI2I), a dual-encoding mechanism shines: the original image is processed separately by the MLLM for semantic consistency and the VAE encoder for visual fidelity, balancing preservation and modification. [Official Qwen-Image Paper, Page 7]
Key Advancements by the Qwen Team
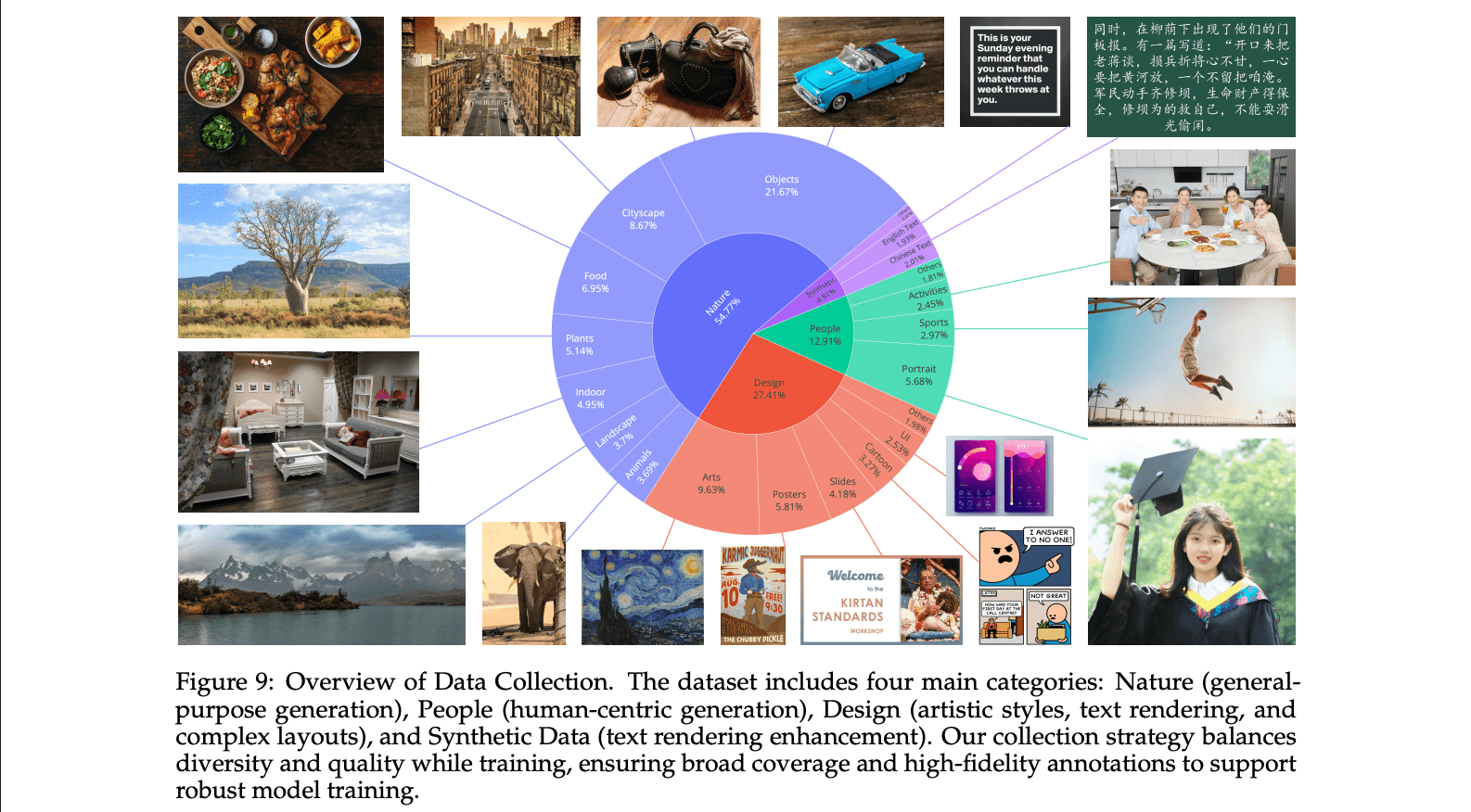
The Qwen team hasn't just assembled existing pieces; they've introduced several innovations to tackle longstanding challenges in text rendering and image editing:
Comprehensive Data Pipeline:
A large-scale pipeline for data collection, filtering, annotation, synthesis, and balancing, emphasizing text-rich content. This addresses gaps in complex text handling, particularly for logographic languages like Chinese. The pipeline processes billions of image-text pairs, with a balanced distribution across major categories: real-world data dominates, comprising Nature (approximately 55%), Design (around 27%), and People (about 13%). Synthetic data makes up roughly 5%, generated through controlled techniques like Pure Rendering, Compositional Rendering, and Complex Rendering to enhance text integration without relying on AI-generated images.
For text-specific enhancement, the dataset is split into English, Chinese, Other Languages, and Non-Text categories, though exact percentages for these splits are not specified. While explicit breakdowns for text lengths (e.g., single-word, short-text, long-text) aren't provided, the synthesis strategies progressively incorporate varying complexities, from simple text on clean backgrounds to intricate paragraph-level layouts in realistic contexts. Balancing strategies include category rebalancing via keyword and image retrieval, hierarchical taxonomy for resampling long-tail distributions, and progressive adjustments to domain and resolution for stable training across scales. [Official Qwen-Image Paper, Page 9-14]
Progressive Curriculum Learning: Training starts with non-text images, progresses to simple text, and scales to paragraph-level descriptions. This step-by-step approach dramatically boosts native text rendering, making Qwen-Image rival proprietary models in English while leading in Chinese. [Official Qwen-Image Paper, Page 16]
Multimodal Scalable RoPE (MSRoPE): A novel positional encoding that builds on Rotary Position Embeddings (RoPE), a technique that encodes positional information in transformers using rotation matrices to unify absolute and relative positioning for improved generalization and sequence handling. MSRoPE improves text-image alignment by handling 2D spatial relationships, enabling better resolution scaling and integrated text generation. [Official Qwen-Image Paper, Page 8]
Enhanced Multi-Task Training: Incorporates T2I, TI2I, and image-to-image (I2I) reconstruction, aligning latents between Qwen2.5-VL and MMDiT for superior editing consistency. [Official Qwen-Image Paper, Page 6,18]
These advancements result in state-of-the-art (SOTA) performance, as evidenced by benchmarks like GenEval, DPG, OneIG-Bench for generation, and GEdit, ImgEdit, GSO for editing. Notably, on text-specific tests like LongText-Bench, ChineseWord, and CVTG-2K, Qwen-Image outperforms existing models by a wide margin. [Official Qwen-Image Paper, Page 1]
While we won't delve too deeply into the training methodology here, Qwen-Image utilizes a progressive curriculum learning approach combined with multi-task training and optimization techniques to refine its performance across generation and editing tasks. [Official Qwen-Image Paper, Pages 15-18]
Vs. GPT-Image-1 (OpenAI's High-Fidelity Text-to-Image Model)

Qwen-Image enters a competitive landscape dominated by models like OpenAI's GPT-image-1 (a GPT-4-class multimodal transformer for text-to-image). While direct apples-to-apples comparisons depend on specific tasks, Qwen-Image's focus on text rendering and editing gives it distinct edges, particularly in open-source accessibility.
GPT-image-1 excels in high-fidelity creation and editing, with strong prompt adherence, world-knowledge synthesis, and enterprise safety features like watermarking. It supports multi-style generation and offers sharper typography than its predecessor, DALL-E 3.
However, Qwen-Image surpasses it in several areas:
Text Rendering: Qwen-Image achieves SOTA results, rivaling GPT-4o (and by extension, GPT-image-1) in English while being best-in-class for Chinese. It handles multi-line, localized, and integrated text seamlessly, where GPT-image-1 struggles with non-alphabetic languages and complex layouts. [Official Qwen-Image Paper, Page 34-38]
Editing Consistency: Through dual-encoding and multi-task training, Qwen-Image maintains better semantic and visual fidelity in tasks like object editing, pose manipulation, and chained edits. Qualitative comparisons show Qwen-Image preserving details (e.g., background structures) more accurately than GPT-image-1. [Official Qwen-Image Paper, Page 34-38]
General Performance: On benchmarks like GenEval and DPG, Qwen-Image demonstrates superior alignment and quality. It's also open-source, unlike GPT-image-1's API-only access, though GPT-image-1 may edge out in speed for low-res drafts. [Official Qwen-Image Paper, Page 1]
Overall, Qwen-Image positions itself as a strong alternative for text-heavy applications, outperforming in bilingual and complex scenarios while matching in photorealism and styles. [Official Qwen-Image Paper, Page 39]
Required GPU Infrastructure to Deploy the Model
Deploying large models like Qwen-Image demands substantial computational resources, particularly for inference and fine-tuning. With 20 billion parameters, a rough estimate for VRAM requirements can be calculated as the number of parameters in billions multiplied by 1.2, yielding approximately 24 GB of VRAM for efficient operation in mixed precision (e.g., BF16).
This estimate accounts for weights, activations, and optimizer states in a streamlined setup, though real-world usage may vary based on batch size, resolution, and optimizations like quantization. For inference, a single high-end GPU like NVIDIA's H100 (with 80 GB HBM3 memory) can comfortably handle Qwen-Image in BF16, enabling fast generation times.
Running Qwen-Image on a Single H100 from Hyperbolic Labs
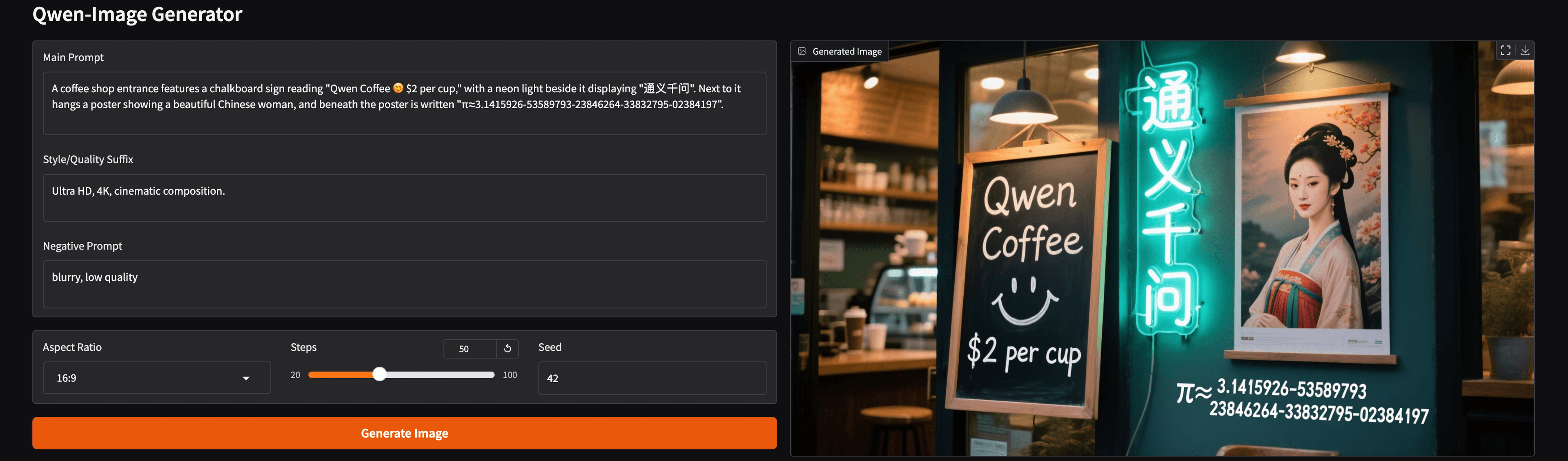
To demonstrate Qwen-Image's practicality, we ran the model in BF16 precision on a single H100 GPU for only $1.49 per hour, provided by Hyperbolic's On-Demand Cloud. This setup allowed for seamless inference and serving via a Gradio endpoint, highlighting the model's efficiency on enterprise-grade hardware. The code for loading the model, generating images, and deploying the interface is below. This code is adapted from the Qwen team's example on the official model card.
First, rent an H100 from Hyperbolic's On-Demand Cloud. Once your instance starts up, copy the ssh command and paste into your terminal. Then, run the following dependency install commands:
pip install git+https://github.com/huggingface/diffusers pip install transformers accelerate gradio pillow torch
Next, we'll need to create and open a python file .
touch app.py nano app.py
Copy and paste the following code, then save and exit the nano editor:
import torch
from diffusers import DiffusionPipeline
import gradio as gr
import tempfile
import os
from PIL import Image
# Load model
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe.to(device)
# Generation function
def generate_image(prompt, style_suffix, negative_prompt, aspect_ratio="16:9", steps=50, seed=42):
# Combine the base prompt with the style suffix
full_prompt = prompt + " " + style_suffix if style_suffix.strip() else prompt
aspect_ratios = {
"1:1": (1328, 1328), "16:9": (1664, 928), "9:16": (928, 1664),
"4:3": (1472, 1140), "3:4": (1140, 1472)
}
width, height = aspect_ratios[aspect_ratio]
image = pipe(
prompt=full_prompt, negative_prompt=negative_prompt,
width=width, height=height, num_inference_steps=steps,
true_cfg_scale=4.0, generator=torch.Generator(device=device).manual_seed(seed)
).images[0]
# Save image as PNG to a temporary file for better download compatibility
temp_dir = tempfile.mkdtemp()
temp_file = os.path.join(temp_dir, f"generated_image_{seed}.png")
image.save(temp_file, format="PNG", quality=95)
return temp_file
# Gradio interface
with gr.Blocks(title="Qwen-Image Generator") as demo:
gr.Markdown("# Qwen-Image Generator")
with gr.Row():
with gr.Column():
prompt = gr.Textbox(
label="Main Prompt",
placeholder="Enter your image description here...",
lines=3
)
style_suffix = gr.Textbox(
label="Style/Quality Suffix",
value="Ultra HD, 4K, cinematic composition.",
placeholder="Additional styling terms to append to the prompt",
lines=2
)
negative_prompt = gr.Textbox(
label="Negative Prompt",
value="blurry, low quality",
placeholder="What you don't want in the image",
lines=2
)
with gr.Row():
aspect_ratio = gr.Dropdown(
choices=["1:1", "16:9", "9:16", "4:3", "3:4"],
value="16:9",
label="Aspect Ratio"
)
steps = gr.Slider(20, 100, value=50, label="Steps")
seed = gr.Number(value=42, label="Seed")
generate_btn = gr.Button("Generate Image", variant="primary")
with gr.Column():
output_image = gr.Image(label="Generated Image", type="filepath")
generate_btn.click(
fn=generate_image,
inputs=[prompt, style_suffix, negative_prompt, aspect_ratio, steps, seed],
outputs=output_image
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", server_port=8080)Finally, we will run the server:
python app.py
You will see the model weights download and eventually the server will be running on port 8080. Hyperbolic's Virtual Machine H100s come with default port forwarding, which is visible on the instance card. Paste this url into your browser, then enjoy creating images with Qwen-Image powered by Hyperbolic!
http://<public_instance_ip>:<public_port>/
The Qwen Team's Conclusion
As articulated by the Qwen team in their research paper:
"Qwen-Image is more than a state-of-the-art image generation model—it represents a paradigm shift in how we conceptualize and build multimodal foundation models. Its contributions extend beyond technical benchmarks, challenging the community to rethink the roles of generative models in perception, interface design, and cognitive modeling. By emphasizing complex text rendering in image generation and addressing classical understanding tasks such as depth estimation through the lens of image editing, Qwen-Image points toward a future in which: (1) generative models do not merely produce images, but genuinely understand them; and (2) understanding models go beyond passive discrimination, achieving comprehension through intrinsic generative processes. As we continue to scale and refine such systems, the boundary between visual understanding and generation will blur further, paving the way for truly interactive, intuitive, and intelligent multimodal agents." [Official Qwen-Image Paper, Page 39]
About Hyperbolic
Hyperbolic is the on-demand AI cloud made for developers. We provide fast, affordable access to compute, inference, and AI services. Over 195,000 developers use Hyperbolic to train, fine-tune, and deploy models at scale.
Our platform has quickly become a favorite among AI researchers, including those like Andrej Karpathy. We collaborate with teams at Hugging Face, Vercel, Quora, Chatbot Arena, LMSYS, OpenRouter, Black Forest Labs, Stanford, Berkeley, and beyond.
Founded by AI researchers from UC Berkeley and the University of Washington, Hyperbolic is built for the next wave of AI innovation—open, accessible, and developer-first.
Website | X | Discord | LinkedIn | YouTube | GitHub | Documentation
:format(webp))
:format(webp))
:format(webp))
:format(webp))
:format(webp))